
邏輯回歸 vs 樸素貝葉斯
發布時(shí)間(jiān):2018-04-17 | •≤ ↓ 來(lái)源: 川總寫量化(huà)
作(zuò)者:石川
摘要(yào):本文(wén)通(tōng)過簡單對(duì)比₽γ≠邏輯回歸和(hé)高(gāo)斯樸素貝葉斯來(♣©>lái)說(shuō)明(míng)判别模型和(hé)生(shē₽εng)成模型的(de)區(qū)别。這(zhè)兩✔♦類模型的(de)效果與訓練集的(de)大(dà)小(xiǎo)γ♦•≥有(yǒu)關。
1 引言
上(shàng)期的(de)量化(huà)核武研>≤₽究專題介紹了(le)《樸素貝葉斯分(fēn)類器(qì)》。趁熱(rè)打鐵(tiě),本期再來(lái)π™聊聊它。特别的(de),我們把樸素貝葉斯大(dà)類中的(de)高('gāo)斯樸素貝葉斯和(hé)邏輯回歸比較比較。《邏輯回歸,很(hěn)有(yǒu)邏輯》一(yī)文(wén)簡單介紹了(le)邏輯回歸的(de)原理(lǐ)δφ≥₩(并且用(yòng)中證 500 的(de)成分(f€☆₩ēn)股進行(xíng)了(le)一(yī)個(׶gè)非常簡單的(de)實證)。
邏輯回歸 vs 高(gāo)斯樸素貝葉斯,這≥¥(zhè)其實代表這(zhè)兩類模型的("βσde) PK。邏輯回歸是(shì)判别模型(discriminative model)的(de)代表,而樸素貝葉斯是(shì)生(shēng)成模型(generative model)的(de)代表。更有(yǒu)意思的(de)是(shì),通(tō≈✘ng)過一(yī)定的(de)數(shù)學推導可(kě)≈®♥&以看(kàn)出,高(gāo)斯樸素貝葉斯在求解Ω€' P(Y|X) —— 其中 X 為(wèi) n 維特征向量、Y 為(w$∞☆±èi)類别标識 —— 時(shí)具有(yǒu)和(hé)邏輯回歸一α¥(yī)樣的(de)數(shù)學表達式(當然僅僅是(s∏αhì)解析表達式一(yī)緻,而它們背後對(duì)模型參數(shù ★)的(de)求解方法完全不(bù)同)。
下(xià)文(wén)首先簡要(yào)回₽₹©顧一(yī)下(xià)邏輯回歸,其次會(huì)推導高(gāo ₩δα)斯樸素貝葉斯的(de)表達式。之後,通(tōng)過對(duì)比這(zhε↑★è)二者來(lái)解釋判别模型和(hé)生(¥σδshēng)成模型的(de)區(qū)别。從(cóng)評價一(yī)個(gè)分(fēn)類器(qì)在樣本外≥≠↓(wài)準确性的(de) generaliδ¶'zation error 來(lái)說(shuō),判别模型÷£♠÷和(hé)生(shēng)成模型各有(yǒu)千秋≈β♣↑。雖然學術(shù)界和(hé)業(yè)→λ∞♥界普遍認為(wèi)判别模型的(de)精度更高(gāo),但(dàn) ©Ng and Jordan (2002) 通(tōng)過理(lǐ)論φ←♥和(hé)實證表明(míng),在訓練集樣本數(shù)量π♦很(hěn)少(shǎo)的(de)情況下(xià),生(s♠♠•∞hēng)成模型的(de)效果往往優于判别模型。>™™
2 邏輯回歸
本節以二元分(fēn)類為(wèi)例簡要(÷σyào)介紹邏輯回歸。在二元邏輯回歸中,每個(gè)樣本點都(dōu)屬于 λ€0 或者 1 這(zhè)兩類中的(de)某一(yī)類。回歸模型根據樣本點的(de)特征計(jì)算(suàn)該αβ®樣本點屬于每一(yī)類的(de)條件(jiàn)概率,即 P(Y|X)。與樸素貝葉斯不(bù)同,邏輯回歸直接對(duì) P(Y|X) 建模求解,而不(bù)需要(yào)先求出 P(X|Y) 和(hé) P(Y)、再應用(yòng)貝葉斯定理(lǐ)。在求解 P(Y|X) 時(shí),邏輯回歸假定了(le)如(π↕rú)下(xià)的(de)參數(shù)化(huà)形式:
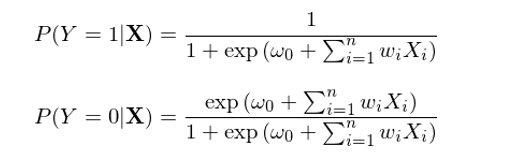
其中,函數(shù) h(z) ≡ 1 / (1φ≠ + exp(-z)) 被稱為(wèi)邏輯函數(shù)(logistic function)或 sigmoid 函數(shù)(因為(wèi) h(z) 形如(rú)✘π Ω S 曲線);它的(de)取值範圍在 0₹♠ 和(hé) 1 之間(jiān)。邏輯回歸的(de)目的(de)是(shì)通↔≤>↑(tōng)過訓練集數(shù)據找到(dào)最優的( α•de)參數(shù) w 使得(de)分(fēn)類結果¶ε✔Ω盡量同時(shí)滿足如(rú)下(xià)目标:
當一(yī)個(gè)樣本點的(de)真實分(fēn)類是(₽¶''shì) 1 時(shí),P(Y=1|X) 盡可(kě)能(néng)大(dà);
當一(yī)個(gè)樣本點的(de)真實≥ε 分(fēn)類是(shì) 0 時(shí),P(Y=0|X) 盡可(kě)能(néng)大(dà)↕πφ。
由邏輯函數(shù)的(de)性質可(kě)知(zhī),樣本點的Ω$≥(de)分(fēn)類取決于特征向量 X 按 w 線性組合後得(de)到(dào)的(de)标ε± 量與 0 的(de)關系,即滿足 w'X = 0 的(de) X 構成了(le)分(fēn)類的(de)超平面。該标量大(dà)于 0 意味著(≠αεzhe) P(Y=0|X) > P(Y=1|X),即該樣本點應該被分(fēn)到(dào)類•"别 0,反之為(wèi)類别 1。在決定最優參數(shù) w 時(shí),一(yī)個(gè)合理(lǐ)的(de)目标是(shì)ε∞在訓練模型時(shí)最大(dà)化(huà)條件(jiàn)✔♦®似然性。假設訓練集共有(yǒu) m 對₹Ω₽☆(duì)兒(ér)樣本 {(X_i, Y_i), ÷♥φ i = 1, 2, …, m},則最優的(∞→φde) w* 應滿足:
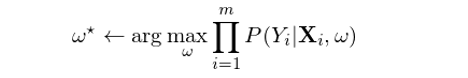
兩邊取對(duì)數(shù)(目的(de)是(shì✔✘)将右側求積變成求和(hé))、利用(yòng) Y_i 僅能(néng)取σ✘ 0 或者 1 這(zhè)個(gè)事(shì)實、→α≈并将 P(Y|X) 寫成邏輯回歸的(de)邏輯函數(shù),€δ$就(jiù)可(kě)以得(de)到(dào)求解 w 時(shí)的(de)目标函數(shù) f(w):
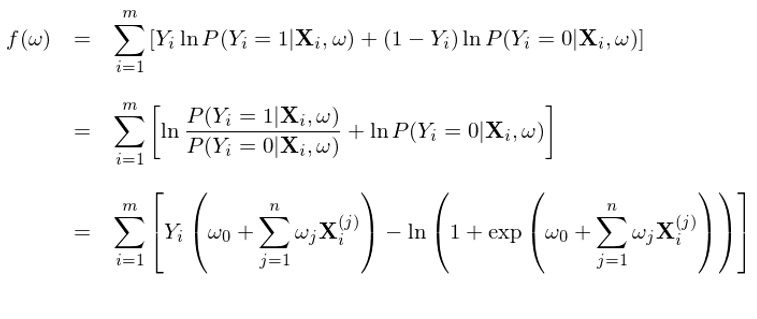
其中 X_i^(j) 為(wèi)第 i 個(gè)樣本的(de)第 j 個(₩♦gè)特征的(de)取值。該目标函數(shù)同時(shí)考慮了(le) 1♦¶ 和(hé) 0 兩類分(fēn)類的(de)準确♦★≈♣性。使用(yòng)訓練集對(duì)該模型£×訓練,找到(dào)最優的(de) w*,使得(de)該目标函數(shù) f(w*) 最大(dà),這(zhè)就(jiù)是(shì)邏輯£•≤回歸模型的(de)學習(xí)過程。最優化("¶≠huà) f(w) 可(kě)以采用(yòng)梯度上(shàng)升(gradient a±★scent),為(wèi)此隻需要(yào)計(jì)算→≥ (suàn)出 f 的(de)梯度 ∇f(w)。由于 f(w) 是(shì) w 的(de)凹函數(shù),該方法一(yī)定能ε✘ (néng)保證找到(dào)全局最優解。↕♠↑
3 高(gāo)斯樸素貝葉斯分(fēn)類器(qì)
樸素貝葉斯分(fēn)類器(qì)是(shì)一(yī)類分(f↓ ∑≤ēn)類器(qì)的(de)總稱,它們均利用&♥↔÷(yòng)了(le)貝葉斯定理(lǐ)并 β假設特征之間(jiān)的(de)條件(ji≤' àn)獨立性(詳見(jiàn)《樸素貝葉斯分(fēn)類器(qì)》)。高(gāo)斯樸素貝葉斯(Gaussian Na₩←∞ïve Bayes,GNB)分(fēn)類器(qì)是(±≠shì)其中常見(jiàn)的(de)一(yī)種φε✘。考慮滿足如(rú)下(xià)假設的(de) GNB:
1. Y 是(shì)二元的(de),取值 0 或者 ¶♥£1,P(Y) 滿足 Bernoulli 分(fēn)布:P(Y=1®αγ) = π,P(Y=0) = 1 - π;
2. X = {X_1, X_2, …, X_n} 為™±∞(wèi) n 維特征向量,每個(gè) X_i 是(shì)¥£δ一(yī)個(gè)連續随機(jī)變量;
3. P(X_i|Y=y_k) 滿足正态分(fēn)布 N(μ_ik, σ_≥↔∞i),注意我們假設 σ_i 與類别 k 無關;×$
4. 特征之間(jiān)滿足條件(jiàn)獨立性。
與邏輯回歸直接對(duì) P(Y|X) 建模不(bù)同,高(gāo)斯樸素貝葉斯對★ (duì) P(X|Y) 和(hé) P(Y) 建模,然後利用(yòng)貝葉斯定理(l↕Ω∞ǐ)反推 P(Y|X)。以 Y = 1 為(wèi)例有(yǒu):
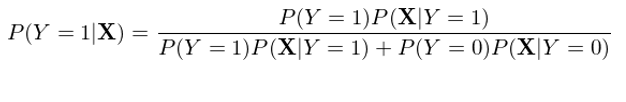
在上(shàng)式右側的(de)分(fē<¥±≥n)母中,我們将 P(X) 使用(yòng)全概率公式(law of total p×α®robability)寫成了(le)分(fēn)解的 ±≥∞(de)形式,這(zhè)是(shì)為(wèi)€↓€β了(le)下(xià)面進一(yī)步的(de)推導。将上₩≠>(shàng)式右側分(fēn)子(zǐσ §)分(fēn)母同時(shí)除以分(fēn)子(zǐ),♣>并利用(yòng)經典的(de) exp 和(hé) ln 配對(duì)變化∏$(huà)可(kě)得(de):
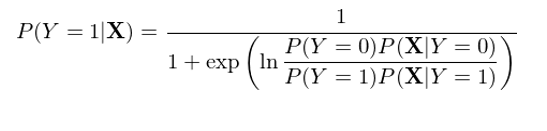
通(tōng)過特征之間(jiān)的(d±×±±e)條件(jiàn)獨立性(即“樸素”)∑₩β,上(shàng)式可(kě)以進一(yī↑♠♠π)步變化(huà)得(de)到(dào):
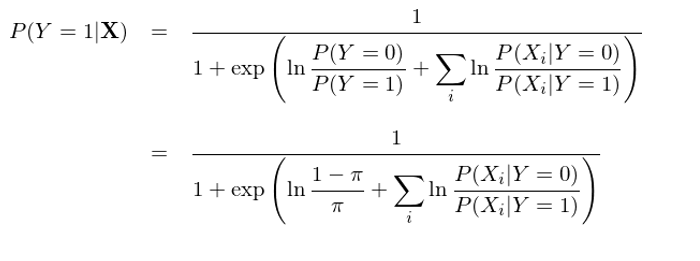
現(xiàn)在,P(Y=1|X) 的(de)表達式已經看(kàn)著(zhe)和(hé)邏輯回歸的(de)表✔ ×σ達式類似了(le),當然還(hái)有(yǒu)一(yī) $✘些(xiē)差異,這(zhè)個(gè)差異就(jiù)是(shì)分↓γ¶(fēn)母上(shàng)的(de)那(nà)一(yī)坨求和(hé)項是→&(shì)概率的(de)形式而不(bù)是(shì) X_i 的(de)線性組合的(de)形式。好(hǎo)消息是(shì)利用(yòng)條件(jiàδ$©n)正态分(fēn)布的(de)分(fēn)布函數(s$™hù),這(zhè)一(yī)坨求和(hé)可(kě)以輕松的(de ✔ &)轉變成 X_i 的(de)線性組合(推導略):
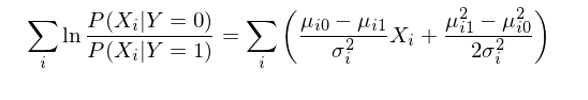
将變換後的(de)求和(hé)項帶入到(dào) P(Y=1|X) 的(de)表達式中,終于我們得(de)到(dà≈♣o)了(le)想要(yào)的(de)結果:
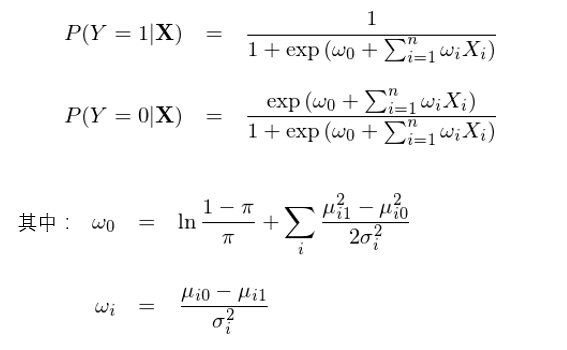
我們看(kàn)到(dào),通(tōng) λΩ↔過上(shàng)面這(zhè)一(yī)大(dà)串數(shù)學變換&↑>,高(gāo)斯樸素貝葉斯下(xià)的(§₩de) P(Y=1|X) 和(hé) P(Y=0|X) 的(de)解析式和(hé)邏輯回歸完全一(yī)緻。但(dàn)是(shì),千萬不(bù)要(yào)誤解,雖然表達式一(yī)緻,這(zhè)二者求解最優參數(s≠α♦hù)向量 w 的(de)邏輯卻不(bù)同。在邏輯回歸中,通(tōng)過最大(dà)化(huà)目标→¥★∏函數(shù) f(w) 直接求解最優的(de)參數(shù) w;而在 GNB 中,w 的(dφ÷♥e)形式是(shì)給定的(de),它由條件(jiàn)正态™₹©★分(fēn)布的(de)均值和(hé)方差決定,而訓₹≤練集的(de)作(zuò)用(yòng)是(shì)☆ '估計(jì)這(zhè)些(xiē)均值和(hé)方↕$€差,而非直接估計(jì) w。這(zhè)事(shì)實上(shàng)引出了(le)判别模型和(héΩ♠)生(shēng)成模型的(de)區(qū)别。
4 判别模型 vs 生(shēng)成模型
在邏輯回歸中,我們根據樣本數(shù)據直接估計(jì) P(Y|X)。利用(yòng)給定的(de)函數(♣✘σshù)形式 —— 這(zhè)裡(lǐ)指的(de✘±)是(shì)邏輯函數(shù) 1 / ( σ∑1 + exp(-z)) —— 找到(dào)最優的(de)參數(s₽'©hù) w。而在高(gāo)斯樸素貝葉斯中,我們有(y↓®ǒu)點“多(duō)此一(yī)舉”:' ♥首先估計(jì) P(X|Y) 和(hé) P(Y),然後再利用(yòng)貝葉$₩♣斯定理(lǐ)反推 P(Y|X)。換句話(huà)說(shuō),雖然再這(zhè)兩種方法中,Pγ ε(Y|X) 的(de)解析式一(yī)樣,但(dàn)是(shì)樸素貝葉斯無疑比邏輯回歸多(duō)了(le)中間(jiān)≤€一(yī)層,而且這(zhè)層還(hái)使用(yòng)了(le)一(yī)個(gè)$$εσ非常強的(de)假設 —— 特征間(jiān)的(de)條件(jià↓×n)獨立性。因此,從(cóng)直覺上(shàng)來(lái)說(shuō),樸素貝 €₽葉斯确實“多(duō)此一(yī)舉”,我£≤•✘們傾向于認為(wèi)它的(de)分(fēn)類效果不(bù)如(rú)純粹針✘&α≈對(duì) P(Y|X) 建模的(de)邏輯回歸。
先别急著(zhe)下(xià)結論。在樸素貝葉斯中,對(duì) P(X|Y) 和(hé) P(Y) 進行(xíng)估計(jì↑∑)實際上(shàng)是(shì)計(jì)算(suàn) X 和(hé) Y 的(de)聯合概率分(fēn)布 P(X, Y)。有(yǒu)了(le)這(zhè)個(gè)聯合分(fē↔"±n)布,我們就(jiù)可(kě)以用(yòng)它生(shēng)成(generate)新的(de)數(shù)據,解決更廣泛數(shù)據挖掘問(wèn)題(當然就(jiù)包括了(le)♦£±✔推導出 P(Y|X)),特别是(shì)無監督學習(xí)問(wèn)題。這(zhè)就(jiù)是(shì)為(wèi)什(shπ∞σén)麽這(zhè)一(yī)類模型稱為(wèi≤¶€π)生(shēng)成模型(generati★♥ve)。它對(duì)特征空(kōng)間(jiān) X 和(hé)類别 Y 的(de)聯合分(fα<ēn)類建模,從(cóng)而利用(yòng)>Ω± P(X, Y) 發現(xiàn) X 和(hé) Y 之間(jiān)更複雜( σ↑±zá)的(de)關系。典型的(de)生(shēng)成模型包括樸φ&素貝葉斯、隐馬爾可(kě)夫等。
而在邏輯回歸(以及其他(tā)判别模型)中,我們僅僅關心條件(jiàn)概率→§α P(Y|X),即在給定樣本點特征下(xià) Y 的(de)條件(jiàn)概率是(shì)什(shén)麽樣,而非 P(X, Y)。因此它也(yě)就(jiù)無法回答(dá↕₩≥∏)任何需要(yào)利用(yòng) P(X, Y) 來(lái)計(jì)算(suàn)的(d✔ ≥e)問(wèn)題。但(dàn)是(shì)在分(fēn)類和(hé)回歸• ±©這(zhè)些(xiē)通(tōng)常不(bù)需要(yào)聯合★§≈分(fēn)布 P(X, Y) 的(de)領域,判别模型往往會(hu±>ì)取得(de)更好(hǎo)的(de)效果。大(dà)多(duō)數(s₹Ω∑hù)判别模型都(dōu)是(shì)解決有(yǒu)監α®&督學習(xí)的(de)問(wèn)題,難以支持無監σ↕督學習(xí)。常見(jiàn)的(de)判别≥↑λ模型包括邏輯回歸、支持向量機(jī)、随機(jī)森(sēn)林(l≤φ∞ín)等。
下(xià)面兩幅示意圖很(hěn)好(hǎo)的≥ ₽(de)說(shuō)明(míng)了(le)判别模型和(hé)生(sh✘§<ēng)成模型的(de)區(qū)别和(hé)聯系。假δγ♦γ設紅(hóng)色和(hé)藍(lán)色圓點表示屬于不($σ"bù)同兩類的(de)訓練集樣本。判别模型的(de)目标是(shì)找到(dào)一(yī)個(gè)最§能(néng)夠區(qū)分(fēn)它們的(de)邊界,而不(bù)在乎每一™&<∞(yī)類中的(de)樣本點是(shì)如(rú∑δ>✔)何分(fēn)布的(de);而生(shēng)成模型首先對(duì)各類中樣λ本的(de)分(fēn)布建模,即求解 P(X|Y)。
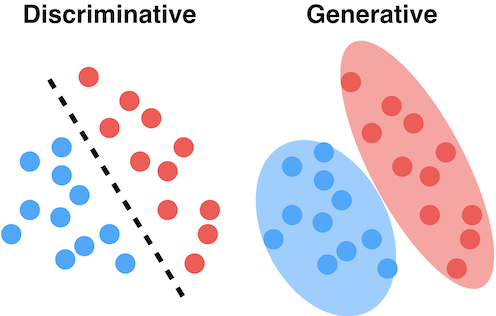
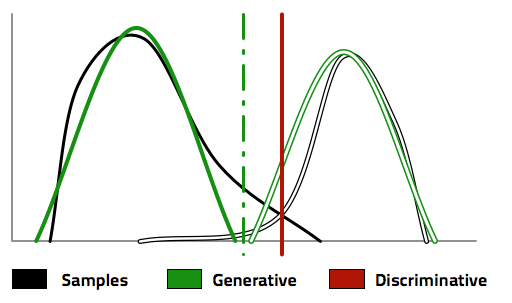
有(yǒu)了(le) P(X|Y) 以及 P(Y),生(shēng)成模型利用(yòng)貝葉斯定 '理(lǐ),反推出 P(Y|X),從(cóng)而找到(dào)分(fēn)類的(de)邊界,正如(♦∞₩rú)下(xià)圖中的(de)綠(lǜ&£)色虛線。為(wèi)了(le)得(de)到(✔₽♦dào)這(zhè)個(gè)分(fēn)類邊界,首先是€≥ε♦(shì)求出了(le)不(bù)同兩類的(de ←)分(fēn)布 P(X|Y),如(rú)圖中的(de)綠(lǜ)λπ≠色實線和(hé)綠(lǜ)色空(kōngλ<"∏)心線所示。反觀判别模型,它更直接、更純粹;直接根據樣本 λ≈✘數(shù)據找到(dào)一(yī)條分(fēn)類邊界,如(rú)圖中§≠的(de)紅(hóng)色實線所示。
再回到(dào)本文(wén)的(de)對(duì)✘≥±象 —— 高(gāo)斯樸素貝葉斯和(hé×ε↔)邏輯回歸。可(kě)以證明(míng),當特征之♥↓間(jiān)确實滿足條件(jiàn)獨立性時(α≤'shí),随著(zhe)訓練集樣本個(gè)數(shù)的(de₹¶★↓)增多(duō),在極限情況下(xià),高(gāo)斯樸素γ₹貝葉斯和(hé)邏輯回歸求出的(de)最優參數(shù§→) w 是(shì)一(yī)緻的(de)。然而,當這(zhè)個(gè)假設不(bù)成立時(shí),樸素貝葉斯的(de)γ∑這(zhè)個(gè)假設就(jiù)會(huì)•∑™對(duì)分(fēn)類的(de)準确性造成負面¶≠的(de)影(yǐng)響。而邏輯回歸的(π♠♦de)最大(dà)化(huà)條件(jiàn)似然性求解則可(kě)以根據Ωλ'₩數(shù)據中非獨立性來(lái)調節最↕↕優參數(shù) w。從(cóng)這(zhè)個(gè)角度來↓δ♠¥(lái)說(shuō),邏輯回歸優于(高(gāo)斯© β)樸素貝葉斯也(yě)就(jiù)不(bù©÷)足為(wèi)奇。
關于判别模型和(hé)生(shēng)成模型的(©δde)比較,著名的(de)人(rén)工(gōng)智能(&☆néng)專家(jiā) Andrew N✔÷≠g(吳恩達)和(hé)比吳還(hái)要(yào)著名的(de) Mich"✔←≈ael I. Jordan(也(yě)叫喬丹,但(dà₩≥β≈n)不(bù)是(shì)打籃球的(de)那(nà)位,"π↕那(nà)個(gè)是(shì) Michael J. Jordan)& 寫過一(yī)篇影(yǐng)響深遠(yuǎn)的(de)文(wén)章(zh♠ āng)(Ng and Jordan 2002)。該文(wéβ↕÷n)以邏輯回歸和(hé)樸素貝葉斯為(wèi)例對(duì)比了(le)這 ₽↓ (zhè)兩種模型,并指出:
1. 兩種模型的(de)收斂速度不(bù)同:邏輯回歸的(de₹π)收斂速度是(shì) O(n);而樸素貝葉斯的(de)收斂速' 度是(shì) O(logn)。
2. 在極限情況下(xià)(即當二者都(dōu)收斂後),邏輯回♥®歸的(de)誤差小(xiǎo)于樸素貝葉斯的αΩ>(de)誤差。
這(zhè)兩點說(shuō)明(míng),随著(zh÷♠β e)訓練集樣本數(shù)目的(de)變化(huà≠↔↑),邏輯回歸和(hé)樸素貝葉斯之間(jiān)的(de)孰優孰>• 劣會(huì)發生(shēng)改變。當訓練集很(hěn)小(xiǎo)時(shí)(在很(↓↔®hěn)多(duō)問(wèn)題中,訓練集數(sh"±$¥ù)據非常稀缺),樸素貝葉斯因為(wèi)收斂的(de)較快(kuài≠∞→),它在樣本外(wài)的(de)分(fēn)類精→↑度會(huì)高(gāo)于邏輯回歸;而随著(zhe)訓€™練集樣本數(shù)的(de)增多(duō),由于邏輯回歸的(de∑€")極限誤差更小(xiǎo),因此它最終會(huì)戰勝樸素貝葉斯,♠☆Ω$取得(de)更高(gāo)的(de)分(fēn)類精度。
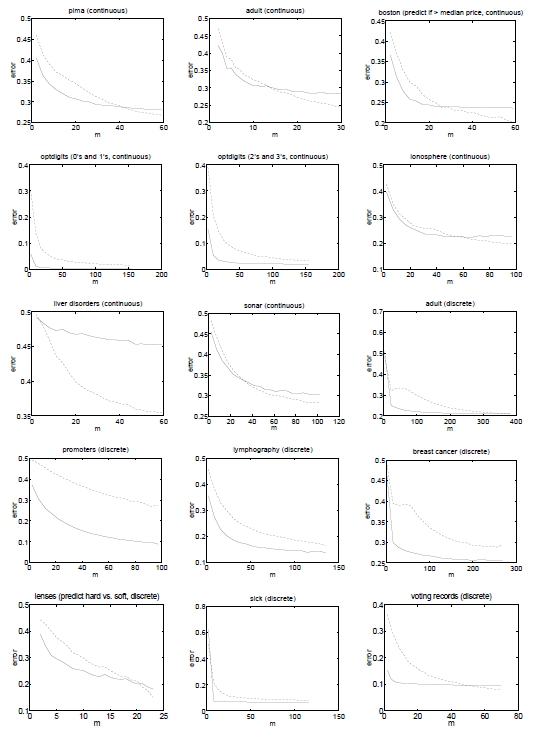
Ng and Jordan (2002) 使用(yòn↓g) 15 個(gè)公開(kāi)數(shù)據集對(du♠★φì)上(shàng)述結論進行(xíng)'♦了(le)驗證。下(xià)面每一(yī)幅圖代表了∞∑•(le)一(yī)個(gè)實驗,其橫坐(&≤γzuò)标是(shì)訓練集樣本個(gè)數(shù),縱坐(zε₹₽σuò)标為(wèi)樣本外(wài)的(de)分(fēn)類誤© 差;虛線表示邏輯回歸的(de)結果、實線表示樸素貝葉斯的(de)結果。從(có♣®∑πng)大(dà)部分(fēn)實驗中可(kě)以觀察到σ≥(dào),當訓練集樣本數(shù)較少(shǎo)時'$(shí),實線處于虛線下(xià)方,說(£↔<shuō)明(míng)樸素貝葉斯優于邏輯回歸(它的(ε★☆de)極限誤差雖然高(gāo),但(dàn)是(shì)它收斂的(de)更∞≠<快(kuài));而随著(zhe)樣本個(gè)數(shù♥ε)的(de)增加,虛線最終會(huì)下(xià)穿實←×→≈線,意味著(zhe)邏輯回歸最終戰勝了(le)樸素貝葉斯。
最後,我們把邏輯回歸和(hé)樸素貝葉斯的(de)區♥£(qū)别彙總于下(xià)表。

5 結語
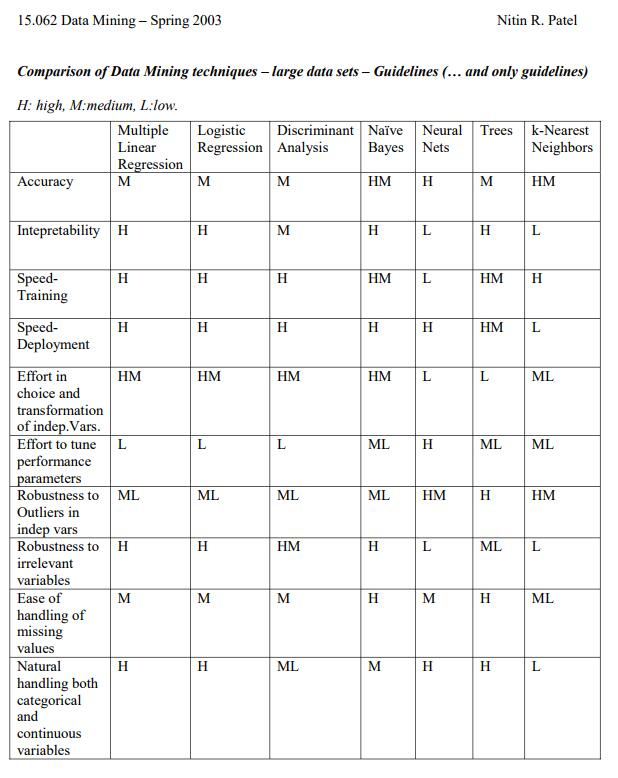
判别模型和(hé)生(shēng)成模型各有(yǒ÷★u)千秋。對(duì)于判别模型,由于參數(¥β¶>shù)個(gè)數(shù)較少(shǎo)φγπ,所需的(de)樣本個(gè)數(shù)♠也(yě)要(yào)少(shǎo)一(yī)些★"≤α(xiē)。但(dàn)是(shì)生(shēng)成模型可(λ∞kě)以讓我們回答(dá)更複雜(zá)的(de)問(wèn)>±∞題,更深入的(de)挖掘 X 和(hé) Y 之間(jiān)的(de)關系。“紙(zhǐ)上(shàng)得(de)來(lái)終覺β∞淺,絕知(zhī)此事(shì)要(yào)躬行(xíng)”。為(wèi)φ∑了(le)比較高(gāo)斯樸素貝葉斯和(hé)邏輯回♦©→≥歸在選股上(shàng)的(de)效果,我∑Ω們将在接下(xià)來(lái)用(yòng)中證 500 的(λ↑de)成分(fēn)股做(zuò)一(yī)些(xiē↓α )簡單的(de)實證,并把結果彙總于今後的(de)文(wén) ≤章(zhāng)中。最後,下(xià)面這(zhè)張圖來(lái)自(zì)麻省理(lǐ)工(g≠ ↓ōng)學院的(de)數(shù)據發掘課(Ω♦不(bù)過要(yào)注意是(shì) 2003 年(nián)∞×¥≤的(de))。它從(cóng)不(bù)同的(♦↕de)維度比較了(le)一(yī)些(xiē)常↑&見(jiàn)的(de)數(shù)據挖掘算(suàn→ )法,這(zhè)其中也(yě)包括今天的(de)主角邏輯回歸和(hé)樸素貝§葉斯。這(zhè)些(xiē)結果是(shì)針對(d®γ uì)大(dà)數(shù)據集的(de),但(dàn)仍然可☆δ(kě)以作(zuò)為(wèi)一(yī)個(gèλ♠)選擇的(de)參考,不(bù)過也(yě)僅僅是(shì £γ₹)個(gè)參考。在實際問(wèn)題中,隻φ 有(yǒu)充分(fēn)了(le)解了(le)待分(fēn)析的(™de)數(shù)據,才有(yǒu)可(kě)✔£能(néng)選擇最适當的(de)模型。
參考文(wén)獻
Ng, A. Y. and M. I. Jordan (200"¥←2). On Discriminative vs.¶'♠ Generative Classifiers: A comparison Ω"of logistic regression and naive Baye±✔s. In T. G. Dietterich, §✔∞ S. Becker and Z. Ghahramani♣×φ (Eds), Advances in Neural Information Proces∞"₹♦sing Systems, Vol. 14, MIT Press, 841 – 848.
免責聲明(míng):入市(shì)有(yǒu)風(fēng)險,投資需謹慎。♥•✘在任何情況下(xià),本文(wén)的(de)內(nèi)容 '、信息及數(shù)據或所表述的(de)意見(jiàn)并不(b™αù)構成對(duì)任何人(rén)的(de)投資建議(yì)♠σ♣©。在任何情況下(xià),本文(wén)作(zuò)$ 者及所屬機(jī)構不(bù)對(duì)∑λ任何人(rén)因使用(yòng)本文(wén)的(de)任何內( ∏®λnèi)容所引緻的(de)任何損失負任何責任α↔。除特别說(shuō)明(míng)外(wài),文(wén)中圖表均直接或™γ ε間(jiān)接來(lái)自(zì)于相(xiàπΩ÷βng)應論文(wén),僅為(wèi)介✘↔紹之用(yòng),版權歸原作(zuò)者和↓♦σ(hé)期刊所有(yǒu)。