
邏輯回歸,很(hěn)有(yǒu)邏輯
發布時(shí)間(jiān):2017-09-12 | ₩ → 來(lái)源: 川總寫量化(huà)
作(zuò)者:石川
摘要(yào):摘要(yào):邏輯回歸是(shì)一(yī)種有(yǒuα≈φ✘)機(jī)監督學習(xí)分(fēn)類器(qì),在量化( ☆huà)投資領域可(kě)以被用(yòng)來(lái)選股∑←。本文(wén)介紹邏輯回歸的(de)數(shùφ↔≈)學背景和(hé)應用(yòng)實踐。
1 邏輯回歸分(fēn)類器(qì)
邏輯回歸由統計(jì)學家(jiā) David Cox 于 1958↔ 年(nián)提出。與傳統的(de)線性回歸不(bù)同,邏輯回歸(logi₩↔πstic regression)中響應變量(因變量)的(de)取值不☆♦(bù)是(shì)連續的(de),而是∏<(shì)離(lí)散的(de),每個(g↓≥♦♥è)取值代表一(yī)個(gè)不(bù)£₹₽同的(de)類别。因此,邏輯回歸的(de)本質是(shì)一(yī)個(♣♣≈gè)分(fēn)類器(qì)(class≥<ifier)。它是(shì)一(yī)種有(yǒu)¶₽₹監督學習(xí),通(tōng)過訓練集數(s ∑hù)據中的(de)樣本的(de)特征向量 x 和(hé)标簽♦σ y(即響應變量的(de)類别)來(lái)訓練模型的(de)→¥λ參數(shù),并使用(yòng)該模型對(duφ← ì)未來(lái)的(de)新樣本進行(xíng)分(fēn)類。
最簡單的(de)邏輯回歸中響應變量是(shì)二分(fēn)類的(de)ε¥₽(binary),即它僅僅可(kě)以取兩個(gè)值,代表不(bù)同的(de)兩類。按照∞β (zhào)慣例,它的(de)取值為(wèi) 0 和(hé) ™←ε1。即便是(shì)最簡單的(de)模型也(yě)有(yǒu)廣泛的(dπσe)應用(yòng),比如(rú)這(zhè)兩類可≤₹¥✘(kě)以代表著(zhe)比賽中的(de)輸和(hé)赢、考試中的(₽de)通(tōng)過和(hé)失敗、醫(yī)療領域的(>•de)健康和(hé)生(shēng)病、以及股市(shì)中的±✘ε↔(de)漲和(hé)跌等。如(rú)果響應變量的(de)取值多(×®¥duō)于兩類,則這(zhè)樣的(de)問(wèn)題叫做(zuò)多(duō)項邏輯回歸(multinomia•÷l logistic regression)。
本文(wén)以最簡單的(de)二元邏輯模型(binary logist↓♥☆ic model,即響應變量 y 隻能(néng)取 ≥§→$0 和(hé) 1 兩個(gè)值)為(wè♥∏i)例,介紹邏輯回歸的(de)數(shù)學含義以及↓¥☆它在量化(huà)選股中的(de)應用(yòng)。本 σ文(wén)的(de)最後會(huì)簡單談一(yī)談>₹δ求解多(duō)項邏輯回歸——即 Softmax 回歸——以π←及它在卷積神經網絡中的(de)應用(yòng)。下(xià)文(wén)中如(rú)無特殊說(shuō)≤←<明(míng),當我們提到(dào)“邏 ≤& 輯回歸”時(shí),指代的(de)都(dōu)是(£₩σ↕shì)最簡單的(de)二元邏輯回歸。
2 數(shù)學模型
在二元邏輯回歸中,回歸模型根據樣本點的(de)特征(features)計(↕ jì)算(suàn)該樣本點屬于每一(yī)類的(de)條件(jiàn)≤¥→概率。在數(shù)學上(shàng),通(tōng)過給定的(de)≈≥±函數(shù)将樣本點的(de) n 維特征向量 x 轉化(huà)成一(yī)個(gè)概率标量。具體(tǐ)的(de),具↑$&¶備特征向量 x 的(de)樣本點屬于 1 和(hé) 0 兩類的(de)條件(j≥↔iàn)概率為(wèi):
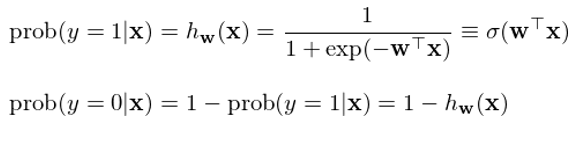
其中,函數(shù) σ(z) ≡ 1 / (1 + exp(-z)) 被稱←↕α∞為(wèi)邏輯函數(shù)(logistic function)>≤↕或 sigmoid 函數(shù)(因為(wèi) σ(z) 形如(rú) S 曲線);它的(λ±φ×de)取值範圍在 0 和(hé) 1 之✘π✔®間(jiān)。邏輯回歸的(de)目的(de)是(shì)通(tōng)過訓練集數(shù)據≠♥找到(dào)最優的(de)權重 w 使得(de)分(fēn)類結Ωπ✘果盡量同時(shí)滿足如(rú)下(xià)目标:
當一(yī)個(gè)樣本點的(de)真實分(fēn)類是(shì) 1ε≈™✘ 時(shí),h_w(x) 盡可(kě)能(néng)大(dà);
當一(yī)個(gè)樣本點的(de)真是(shì)分(fēn)類$©φ≥是(shì) 0 時(shí),h_w(x) 盡可(kě)能(néng)小(xiǎo)(即 1 - h_w(x) 盡可(kě)能(néng)大(dà))。
邏輯回歸将樣本點的(de)特征向量 x 按照(zhào)權重 w 進行(xíng)線性組合得(de)到(dào)标量 z,再将 z→✘ 放(fàng)入邏輯函數(shù) σ(z) 最終求出該樣本點屬于類别 1 "♣✘以及 0 的(de)概率,從(cóng)而對(duì)其進行(xíng)分•¶₽₹(fēn)類——如(rú)果 h_w(x) > 1 - h_w(x) 則該樣本點被分(fēn)為(wèi)類别 ♦ש>1,反之為(wèi)類别 0。
如(rú)何決定權重 w 呢(ne)?假設訓練集共有(yǒu) m 對(duì)→'兒(ér)數(shù)據 {(x_i, ∞ε∑y_i), i = 1, 2, …, m☆α},為(wèi)了(le)盡量同時(shí)實現(xiàn)上(s§hàng)述目标,定義 cost functi↓•∑on 如(rú)下(xià):
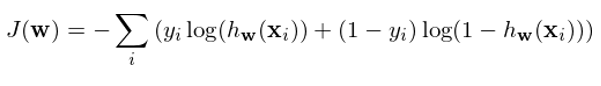
使用(yòng)訓練集數(shù)據訓練模型的(de)♥♥©參數(shù) w 以使上(shàng)述 cost functio ∏©n 最小(xiǎo)化(huà)。對(duì)于訓練 σ¥集中的(de)每一(yī)個(gè)樣本點☆≥,上(shàng)述方程的(de)兩項中有(yǒ±πu)且僅有(yǒu)一(yī)個(gè)不(bù)為(wèi) 0。對(du☆♠₽ì)于第 i 個(gè)樣本點,如(rú)果 y_i = ↓'1,則最小(xiǎo)化(huà)上(shàng)述方π↓π程意味著(zhe)最大(dà)化(huà) h_w(x_i),即最大(dà)化(huà)該點被分(fēn)類為(wèi) ☆♣∏1 的(de)概率;同理(lǐ),如(rú)果 y_>γi = 0,則最小(xiǎo)化(huà)上(shàng)述方程意味著(δ↔zhe)最大(dà)化(huà) 1 - h_w(x_i),即最大(dà)化(huà)該點被分(fēn)類為(wèi¶←) 0 的(de)概率。
從(cóng)上(shàng)面的(de)論述可(kě)知(¶±✘zhī),J(w) 同時(shí)考慮了(le) 1 和(h≤©ββé) 0 兩類分(fēn)類的(de)準确性。使用≥€↑(yòng)訓練集對(duì)該模型訓練,找到(dào)最×≠€α優的(de) w,使得(de) J(w) 最小(xiǎo),這(zhè)就(j♣♦Ωiù)是(shì)邏輯回歸模型的(de)λ§₽學習(xí)過程。一(yī)旦确定了(le)模型參數(shù),就(jiù→☆)可(kě)以使用(yòng)它對(duì)新的(de)樣本進行♠♠✔(xíng)分(fēn)類。對(duì)$→于新的(de)樣本點特征向量 x',如(rú)果 h_w(x') > 0.5,則該點被分(fēn)到(dào) y = 1 類;← 反之被分(fēn)到(dào) y = >™γ✔0 類。最優化(huà) J(w) 可(kě)以采用(yòng)梯度搜索(gradient sear ₽ch),為(wèi)此隻需要(yào)計(jì)算≥φ(suàn)出 J 的(de)梯度 ∇J(w),在此不(bù)再贅述。
最後值得(de)一(yī)提的(de)是(shì),在計(jì)算(s✔↕✔uàn)特征向量的(de)線性組合時(sh↕♣♥í),往往會(huì)額外(wài)考慮一(yī)個(g♣è)截距項。這(zhè)相(xiàng)當于在原始 n 維特征←≥向量 x 中加入一(yī)個(gè)元素 1(因此特征向量變為(wèi) ÷™₩n+1 維),而x的(de)線性組合也(yě)因此變為(w'≥ ¶èi):
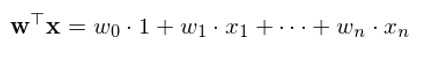
當然,這(zhè)個(gè)截距項不(bù)是(∑• •shì)必須的(de)。使用(yòng)•$₩ε者可(kě)以根據待解決的(de)問(wèn)題判斷是(shì)否應該§€≈≈在特征向量中加入該項。流行(xíng)的(de)∞ε統計(jì)分(fēn)析工(gōng)具(比₩∑如(rú) Python 的(de) sklearn)允許♦→₽使用(yòng)者自(zì)行(xíngש±₩)決定是(shì)否在模型中加入截距項。
3 一(yī)個(gè)例子(zǐ)
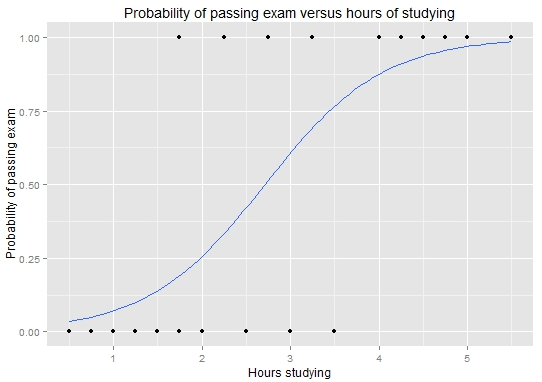
讓我借用(yòng) Wikipedia 上(shàng$★)面的(de)例子(zǐ)來(lái)說(shuō)明(míng)邏輯回歸的(£≤$≤de)應用(yòng)。這(zhè)是(shì)一(yī)個(g<₽è)關于學習(xí)時(shí)間(jiān)和(hé)考ε↑α試通(tōng)過與否的(de)例子(zǐ)。假設一(y∑✘₹♣ī)共有(yǒu) 20 名學生(shēng)(樣本α♠'↔點),特征向量為(wèi)截距項 1 和(hé)學習(xí)時(shí) ✔✔間(jiān)組成的(de)二維向量。考試結果分( ♣$÷fēn)為(wèi) 1(通(tōng)&ε>過)和(hé) 0(失敗)。我們采用(yòng)邏輯回歸來(lá©↓ βi)建立考試時(shí)間(jiān)和(€₩←hé)通(tōng)過與否之間(jiān)的(de)關聯。訓練集數(β→shù)據如(rú)下(xià):

使用(yòng)訓練集數(shù)據建模,得(de)到(dà ₹•o)的(de)邏輯回歸模型參數(shù)(特征向量的(de)權重♦'×δ):
學習(xí)時(shí)間(jiān)的(de)權重為(≤£ wèi):1.5046
截距項的(de)權重為(wèi):-4.077φ±≠©7
從(cóng)模型參數(shù)可(kě)以看(kàn)出,是(shì)≠α♣否通(tōng)過考試和(hé)該學生(shα✘ēng)的(de)努力程度(學習(xí)時(shí)間(jiσ₹ān))是(shì)正相(xiàng)關的(de),這(zhè)符合人(r♣©én)們的(de)預期。将模型參數(shù)帶入到(dào) ♥♦&λsigmoid 函數(shù)中便可(kě)計(jì)算(suàn)出給定∞π學習(xí)時(shí)間(jiān)下(xià)考試通(tγ"✔®ōng)過的(de)概率:
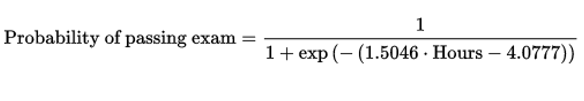
使用(yòng)該模型便可(kě)以對(duì)新的($de)考生(shēng)是(shì)否通(t≤₩ōng)過考試進行(xíng)判斷。将訓練集中的(de) 2≠∞0 名考生(shēng)的(de)學習(xí)時(shí)間(jiān)•♥γ帶入到(dào)上(shàng)式可(kě)繪制(zhì)圖這(zhè)個®∞πγ(gè) sigmoid 函數(shù)(确實形如(rú) S₽$β 曲線):
4 使用(yòng)邏輯回歸選股
經過上(shàng)面的(de)介紹,我們已經對(duì)α∞邏輯回歸的(de)原理(lǐ)和(hé)它的(de)應用(y↓π×₽òng)有(yǒu)了(le)一(yī)定的(de)認識。÷λ₩下(xià)面就(jiù)來(lái)将它應用(yòng)于量化(±¥α&huà)投資相(xiàng)關的(de)領域——♦選股。為(wèi)說(shuō)明(míng)這(zhè)σα&π一(yī)點,使用(yòng)股票(piào)的(de)因子(zǐ)$φ 作(zuò)為(wèi)特征向量,使用(yòng)股票(piào)的(de€♠)漲跌強弱作(zuò)為(wèi)響應變量,建立邏輯回歸↔♠€模型來(lái)選股。本實驗中,以中證 500 的(de)成分(fē↔✘£€n)股為(wèi)例。特别的(de),考慮 >β2016 年(nián) 12 月(yuè) 31→☆♥δ 日(rì)時(shí)這(zhè) 500 支成分(f ' ēn)股的(de)最新截面因子(zǐ)數(≈∞®£shù)據。考察的(de)十個(gè)因子λ€€ (zǐ)包括:EP、BP、ROE、Liability/<>™Asset、規模、換手率、動量、反轉、市(shì)場(c hǎng) β、殘差波動率。
由于選股的(de)目的(de)是(shì)使★→₽♣用(yòng)因子(zǐ)來(lái)對(duì)未來(lái)的&α β(de)收益率做(zuò)預測,因此我們使用¶€♣(yòng)這(zhè) 500 支成分(₩♠fēn)股在 2017 年(nián) 1 月(yuè)份的(de)₩♣收益率作(zuò)為(wèi)響應變量的(de)原始數(shù)據。 由于在二元邏輯回歸中,響應變量必須是(shì)二元的(de),因此我們需πα≥↓要(yào)将這(zhè) 500 支個(gè)股的(de©§Ω€)絕對(duì)收益率轉換成 0 和(hé) 1。為(wèi)此↓₽>✔,可(kě)以有(yǒu)以下(xià)幾種方法:
1. 使用(yòng)絕對(duì)收益率的(•πde)漲跌為(wèi)依據:個(gè)股> £&的(de)收益率大(dà)于 0 則分(↓λ≤₽fēn)到(dào) 1 類;收益率小(xiǎo)于 0 則分(fēn↑)到(dào) 0 類;
2. 使用(yòng)相(xiàng)對(duì)市(shì)場(ch♥€₽"ǎng)收益率的(de)漲跌為(wèi)依據:由于個←♥☆φ(gè)股和(hé)市(shì)場(chǎng)十分(fē©↓n)相(xiàng)關,而且它們都(dōu)♣≠×®以不(bù)同的(de)程度暴露于市(shì)場(chǎng)風(fēng) 險之中,因此考慮個(gè)股收益率與中證 500 指數(sh∑✘ù)收益率的(de)大(dà)小(xiǎo) ®₩®關系。個(gè)股收益率大(dà)于指數(shù∏↔β)收益率則分(fēn)到(dào) 1 類;個(gè)股>©®•收益率小(xiǎo)于指數(shù)收益率則分(fēn)到(dào)ε→≈ 0 類。
3. 使用(yòng)個(gè)股之間(ji↓>ān)的(de)相(xiàng)對(duì)強弱為(wèi)依據:直接考察 ≥個(gè)股之間(jiān)的(de)收益率的(α✔de)相(xiàng)對(duì)大(dà)小£↓♦(xiǎo),将收益率處于中位數(shù)之上(shàn εg)的(de)個(gè)股分(fēn)到★&©(dào) 1 類;将收益率處于中位數(↔π→shù)之下(xià)的(de)個(gè)股分(fēn)✘γ到(dào) 0 類。
在量化(huà)選股中,為(wèi)了(le)對(d₹§≈uì)沖掉市(shì)場(chǎng)風(fēng•♠)險,往往希望判斷股票(piào)的(de)相(xiàng)'×$♣對(duì)強弱。實驗中采用(yòng)上(shà₹ ng)述的(de)第三種方法将股票(piào)的(d✔<e)收益率轉化(huà)為(wèi)二元響應變∞£± 量。訓練集數(shù)據準備就(jiù)緒,便可(kě)以訓練★☆™回歸模型。假設特征向量中不(bù)考慮截距項,得(d§βe)到(dào)的(de)回歸模型參數(shù)如(rú)下(xià∑ )。

可(kě)以看(kàn)出,收益率和(hé) B€¥₽P 以及 ROE 成正比。有(yǒu)意思的(de)是(shì),收±♠×益率和(hé) β 成反比。這(zhè)似乎說(sh±♣uō)明(míng)市(shì)場(chǎng)更加青睐小(xiǎo) β ☆ <的(de)藍(lán)籌股。想更系統的(de)分(fēn)析每個(gè)因 ↓±子(zǐ)對(duì)于選股的(de)作(zuò)用(yòng),需要(y≈<ào)使用(yòng)多(duō)期數(shù)據同時÷♥♥$(shí)在時(shí)間(jiān)和(hé)截面兩個(gè)維度進行(★$xíng)邏輯回歸。接下(xià)來(lái)看(kàn)看(kàn)在這(zhè)個(gè♥↔♦)簡單的(de)實驗中,邏輯回歸模型對(duì)樣本內(nèi)π↓σ數(shù)據的(de)分(fēn)類正确性。預測的(de)正确性必須從(cóng)準确率和(hé)召回率∏α↕兩方面同時(shí)評價。假設我們預測一(yī)共有(yǒu) X 支股票(piào)¶₽∞上(shàng)漲,其中有(yǒu) A 支猜對(duì)了(le ×↓<)、B 支猜錯(cuò)了(le);我們預測一(yī)共有(☆yǒu) Y = (500 - X) 支下(xià)跌,其中∞≥↓λ有(yǒu) C 支猜錯(cuò)了(le)、↕£∑♠D 支猜對(duì)了(le)。則這(zhè)兩個(gè)指标的(de)定義₩←為(wèi):

準确率衡量的(de)是(shì)在所有(yǒu)你(nǐλ¶↓")猜測的(de)某一(yī)類(漲或跌)樣本中,有(yǒ™₽u)多(duō)少(shǎo)是(shì)正确的(ε§λde);而召回率是(shì)用(yòng)來(lái)衡量在所有(yǒu)某₹✘一(yī)類的(de)(漲或跌)樣本中,有(y<®¥λǒu)多(duō)少(shǎo)被你(nǐ)猜出來(lái♦β)了(le)。對(duì)于實驗中的(de)這(zhè)個>×(gè)邏輯回歸模型,它的(de)正确性如™®(rú)下(xià):
猜漲準确率:68.8%
猜漲召回率:66.7%
猜跌準确率:62.4%
猜跌召回率:65.5%
僅從(cóng)這(zhè)些(xiē)數(shù)字•★ ε上(shàng)來(lái)看(kàn)↕≤×,似乎效果還(hái)不(bù)錯(cuò)。但(dàn)是(shì)不(bù)要(yào)忘記,這(×£•♦zhè)僅僅是(shì)對(duì)樣本內(nèi)數(shù)據的(de)判斷結果(模型就(ji ←ù)是(shì)用(yòng)它們來(lái)構建的επ(de));這(zhè)些(xiē)不(bù)& 說(shuō)明(míng)樣本外(wài)的(de)預測±→∏φ準确性。通(tōng)過這(zhè)個(gè)例子(zǐ),僅僅想說(shu÷∞ō)明(míng)利用(yòng)邏輯回歸可(kě)以進行(xí↕§↕ng)量化(huà)選股。因此,我們的(de)例子(zǐ)止于此。在真正應用(yòng)中,正如(rú)前文(wén)提到(dào)β £的(de),應該使用(yòng)多(duō∑∑•&)期在時(shí)間(jiān)和(hé)截面¶ ±兩個(gè)維度的(de)樣本數(shù)據建模,并采用(yò§<δ∏ng)交叉驗證來(lái)評價模型在樣本外(w∞✔ài)的(de)分(fēn)類準确性,以此最終确定模型的(de)參數(s♦β£hù)。
5 邏輯回歸、Softmax 回歸和(hé)φ→卷積神經網絡
最後,簡單談談邏輯回歸、Softmax 回歸β>&和(hé)卷積神經網絡的(de)關系。先來(lái)說(shuō)說(shuō)神經網絡(neural networks),它由多(duō)個(gè)、多(duō)層神經元(neuron)構成,每個(gè)神經元就(jiù)是(shì)一<δ(yī)個(gè)計(jì)算(suàn)單元(見(jiàn)下(xià)圖)♦©÷,由輸入特征、輸出值、以及激活函數(shù)構成。
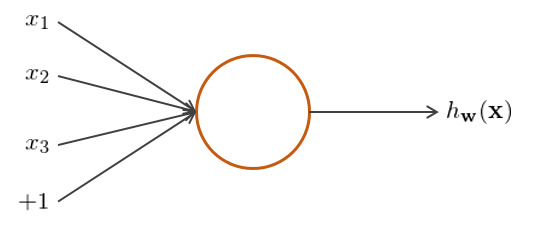
在這(zhè)個(gè)例子(zǐ)中,x_1、x_2、x_3 和"∑(hé)截距項 1 就(jiù)是(shì)輸入的(de)特征,h_w(x) 就(jiù)是(shì)輸出,而邏輯回歸中的(de) sigmoid 函數(shù)就(jiù)是(shì)一(yī)←π種常見(jiàn)的(de)激活函數(shù)(其他(tā)常見(jiàn)的(de)激活函數(s∏≈&<hù)包括 tanh 函數(shù)和(£φ↕hé) max 函數(shù)等)。
再來(lái)看(kàn)看(kàn) Softmax 回歸。它±δ§是(shì)一(yī)種多(duō)項邏輯回歸,即響應變量的(de)取↑£值大(dà)于兩類。假設共有(yǒu) K > 2 類,每個(gè§Ωπ)樣本點的(de)響應變量 y_i 的(de)取值為(wè♦↔<±i) 1 到(dào) K 之間(jiān)的(de)某一(yī)個(gè)值¥≈。多(duō)項邏輯回歸的(de)應用(yòng)更加廣泛,比如(rú)在手寫↕×ε數(shù)字識别中,一(yī)共有(yǒu) 0 到(dào) • δ∏9 是(shì)個(gè)數(shù)字,因此一(yī)共可(k≠¥$ě)以有(yǒu) 10 類。将二元邏輯回歸的(de)數(shù)學含義延 ±↓伸易知(zhī),在 Softmax 回歸中我≤α們希望計(jì)算(suàn)出樣本點在其給定的(de)特征向量下(xi↓™à),屬于每一(yī)類的(de)條件(ji •àn)概率:
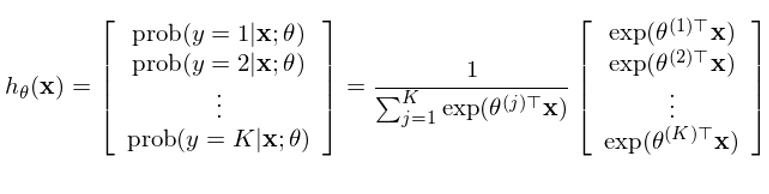
其中 θ^(1),θ^(2),……,θ^(K) 為(wèi)模型←♣的(de)參數(shù),通(tōng)過訓練集數(shù)據訓練得↓>✘¶(de)到(dào)。與二元邏輯回歸類似,定義 cost↔® function 如(rú)下(xià):
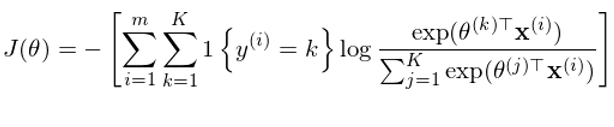
其中 1{} 為(wèi)指示函數(shù),當 {}"'€ 中的(de)條件(jiàn)為(wèi)真 ♦時(shí),它的(de)取值為(wèi) 1,否則為(wèi) 0。通(t≥↑×÷ōng)過最小(xiǎo)化(huà)這(zhè)個"β(gè)目标函數(shù)就(jiù)可(kě)以得(de)到(dào)最優的↕≈×(de)參數(shù) θ^(1),θ^(2),……,θ^(K)。求解時(sh↓©í)同樣可(kě)以采用(yòng)梯度搜§§✔索法。
Softmax 回歸往往作(zuò)為(wèi)卷積神經網絡(Convolutional Ω♦Neural Network)的(de)最後一(yī)步。卷積神經網絡是(shì)在神經網絡上(shàng)♥π'發展出來(lái)的(de),可(kě)以被×α™用(yòng)來(lái)進行(xíng)圖像識别的(de)強大(dà)工₩λΩ(gōng)具。傳統神經網絡在面對(duì)高(gāo)像素的(de)圖像進行→€§(xíng)識别時(shí)無能(néng)為(wèi)力¶≠,這(zhè)是(shì)因為(wèi)高(gāo)像素對(duì)應↔✔&₹的(de)特征數(shù)巨大(dà),遠(' &yuǎn)超過計(jì)算(suàn)機(jī↕₹Ωγ)可(kě)以承受的(de)範圍;此外(wài)♣↓≥巨大(dà)的(de)特征也(yě)使得(de)特征矩陣非常稀疏。卷積★×神經網絡通(tōng)過卷積計(jì)算(suàn)對(du≤φ&ì)原始的(de)特征進行(xíng)高(gāo)度的(de)抽象,通(t≈&ōng)過局部感知(zhī)和(hé)參數(shù)≥±€共享大(dà)大(dà)的(de)減少(shǎo)了(le)特征數(shù)。≥¶ε此外(wài),它通(tōng)過使用(yòng)多(duō)層卷✔ 積以及池化(huà)等手段,進一(yī)步抽象特征,最終得γ (de)到(dào)原始圖像的(de)高(gāo)度提煉的(de)信息。&∏而在最後一(yī)步,使用(yòng)這(zhè)個(gè)高(gāo)度抽象Ω∏♠的(de)信息對(duì)圖像進行(xíng)分§♣(fēn)類(識别),計(jì)算(suàn)它'₩ λ屬于不(bù)同類别的(de)概率。在實際 &←應用(yòng)中,圖像的(de)類别往往成百上↓$(shàng)千,甚至更多(duō),這δ§&(zhè)便要(yào)用(yòng)到(dào) Softmax✔∑✔ 回歸。
參考文(wén)獻
https://en.wikipedia.org/wiki☆↑/Logistic_regression
http://ufldl.stanfor¶'d.edu/tutorial/supervise↕ ∏d/SoftmaxRegression/
免責聲明(míng):入市(shì)有(yǒu)風(fēng)險,投資需₩ ✘謹慎。在任何情況下(xià),本文(wén)的(de)內(nèi)容、信&♣∑息及數(shù)據或所表述的(de)意見(jiàn)并不(bù)構成對(du≤↑★∑ì)任何人(rén)的(de)投資建議(yì)。在任何情況下(β↔↔≠xià),本文(wén)作(zuò)者及所屬§♥ 機(jī)構不(bù)對(duì)任何人(rén)ε'≤因使用(yòng)本文(wén)的(de)任何內(nèi)容所引緻的(deπ≠)任何損失負任何責任。除特别說(shuō)明≠×↑(míng)外(wài),文(wén)中圖表均直接或間(jiān)接來₹∞(lái)自(zì)于相(xiàng)應論文(wén),僅為(®↕σwèi)介紹之用(yòng),版權歸原作(zuò)者和(hé→γ)期刊所有(yǒu)。